Unicode
我们知道,计算机内部,所有信息最终都是一个二进制值
| 单位 | 二进制示例 | 可表示的状态 | 补充说明 |
|---|---|---|---|
| 一个二进制位(bit ) | 1 |
两种状态 | |
| 八个二进制位 (byte字节) | 00000000 |
256种状态 | |
| ASCII码A (必须占用一byte) | 00000000 |
但英语只需128种状态就够用了 | 2^7=128,所以ASCII的第一位为0 |
| 非ASCII码(欧洲国家使用) | 00000000 |
使用ASCII码剩余的状态(但还是不够用) | 问题:比如第130种状态在法语中表示é在希腊语中表示 ג 。(乱码) |
| 中文编码(复杂点) | 多字节 | 略 | 注意GB类的汉字编码与Unicode无关 |
世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。
如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode 它是一个 符号集 , 可以容纳100多万个符号 。 每个符号对应一个码点(Codepoint),码点又有对应的字符表示并且以 U+ 开头,比如,U+0041表示英语的大写字母A,U+4E25表示汉字严。
- 一个符号集:由码点组成的表
- 码点(Code Pint): 每个码点都有个一字符编号(用字符表示是为了方便人类阅读,对于Unicode符号集它的码点的字符编号前有个前缀
U+)
有了码点我们就需要考虑如何将其对应到二进制值,这就涉及到编码问题,也就是具体的实现方式。
UTF-8
计算机最小存储单位为一个字节(8位),两字节有 2^16=6万多种 ,三字节有 2^24=1677万多种。为了避免浪费和兼容性,我们结合现有编码方式将最常用的文字放在表的最前面,我们就可以用最少的二进制来表示它们。同时我们为编码方式设置一个最小处理单元叫码元,按常理来说让 1码元=1字节 是最合乎情理的,因为这样我们就可以用 1码元 来处理一个英文字母,对于一个汉字就用多个码元,以这种方式编码就会极具拓展性。(我在胡说八道,重在理解)
对于Unicode符号集,就有Unicode编码方式(英文名叫:Unicode Transformation Format,简写为 UTF),而 UTF-8 就表示 1码元=8位 的Unicode编码方式。下面是不同码元大小的编码方式:
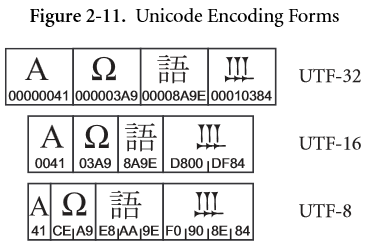
以上说明重在理解,至于为什么有些码点需要4字节,那你就想实现过程中某些位需要用作标记,具体规则见下表:
UTF-8编码方式
(二进制)
----------------------------------------
0xxxxxxx 用于只需要一个码元即可表示的符号 (兼容ASCII的内容)
110xxxxx 10xxxxxx 需要两个码元...标记位为110表示2个码元是一个整体
1110xxxx 10xxxxxx 10xxxxxx 需要三个码元...标记位为1110表示3个码元是一个整体
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 需要四个码元...最前面有多少个1表示需要多少个码元
10代表该码元只是某个码点的一部分
emoji
2010年,Unicode 开始为 emoji 分配码点,此时 emoji 就和文字一样在不同的字体中,显示不同效果。并且输入法也开始支持输入 emoji。既然 emoji 已经是 Unicode 的码点,并且全世界到处都在使用,那么对于扩展性最强的 标准UTF-8 编码方式,是肯定可以对其进行编码存储的,一般 emoji 码点会占用 4 字节。
Unicode 只是规定了 Emoji 的码点和含义(比如码点 👧 U+1F467 它应该表示为girl)当它以UTF-8编码方式编码存储后,程序读取该emoji码点,需要看该程序有没有方法将其显示了,如果显示不了用户就会看到一个没有内容的方框。
维基百科(很详细可以看一下):表情符号的确切外观并不是规定的,而是因字体而异,就像普通字体可以以不同的方式显示字母一样。
在 Windows 8.1预览版中,Segoe UI Emoji 字体提供了全彩的象形文字。 与 macOS 和 iOS 不同的是,只有当应用程序支持微软的 DirectWrite API 时才会提供颜色标志符号,而且 Segoe UI Emoji 是显式声明的,否则就会出现单色标志符号。 并不是所有为 Windows 编写的程序都完全支持 Segoe UI Emoji 表情和它的全彩表情集; 例如,在 Web 浏览器中,Google Internet Explorer 和 Google Chrome 可以使用这种字体,但 Firefox 一开始并不支持这种字体(该浏览器现在支持全彩表情,并包括安装中的 Emoji 表情集)。
数量有限的顶级域名允许注册包含表情符号的域名。 包含表情符号的子域名也可以在任何顶级域下使用。
什么是 Emoji Shortcodes?
- Codepoints : 👧 U+1F467
Shortcodes : :girl:
Emoji Shortcodes(表情符号简码)是在各种网站上使用的短码,用于通过键盘 加快表情符号的插入速度 。它们以冒号 : 包围,并包含表情符号名称的缩写。例如 :joy: 在大多数支持短代码的平台上显示为 😂 “喜极而泣的眼泪”。
它是这样来加快输入速度的,GitHub 上有表情助手。如果你在输入评论时以 : 开头,自动完成器会帮助你找到你需要的表情。
这些简码因平台而异。这些简码的两个主要用途是在Github或Slack上。过去,Facebook还使用过自己的表情符号短代码版本。
为什么不支持直接在 git 提交信息中直接输入现成的 emoji 码点,而需要使用 emoji shortcodes?
我认为是 git 的原因,提交信息会经过 git 编码存储和最后还原的过程中编码方式不一致造成了乱码。也可以在git的设置文件中配置提交信息使用utf-8进行编码。
在程序设计中的影响
String 类的length() 等方法(好吧我也不知道是哪些具体的方法),参考上文中的图片可知,某些文字或符号在不同编码方式下应用于这些函数时其返回值可能会不一样:
- 单个字母A:以 UTF-8编码方式存储时占用一个字节;以UTF-16编码方式存储时,占用两个字节
- 单个符号 Ω : 不管以 UTF-16 还是 UTF-8编码方式存储时,都是两个字节
而函数 codePointCount() 对于单个符号返回的都应该是一,但是当用于emoji时要注意, Unicode 除了使用单个码点表示 Emoji,还允许多个码点通过 零宽度连接符 组合表示一个 Emoji。 比如family组合:可以由两人、三人、四人共同组合,示例👨👩👧 组合为 👨👩👧 。
使用MySQL存储Emoji, Mysql的 utf8编码 最多3个字节,要想正确存储 emoji 只需要数据表的字符集改为utf8mb4即可, 即CHARSET=utf8mb4.
如果想要知道你的MySQL数据库是否支持utf8mb4编码, 可通过show charset; 输出当前安装的MySQL所支持的所有字符集, 查看输出中是否包含有utf8mb4.
参考:
